Learning Hub 2.0 — platform refresh research
End-to-end mixed-methods research informing a refresh of Cisco Meraki's flagship self-paced learning platform.

Context
Cisco Meraki’s Learning Hub is the flagship self-paced training platform used by network administrators learning the Cisco Meraki dashboard. The platform was due for a significant refresh (“Learning Hub 2.0”) and the team needed evidence to decide what to keep, what to change, and what to add.
“Refresh the platform” is an open brief, and the ambiguous part was locating where the problem actually lived. Was people’s frustration about the content itself, or about how the platform was structured and navigated? Those diagnoses point to very different redesigns, and the research’s main job was to settle that question before the team committed to a direction.
I was the lead researcher on the effort, partnering with a designer and contributing research throughout a roughly three-month engagement.
What I did
The work was end-to-end: study design, instrument creation, recruitment, testing, synthesis, and a final insights deliverable to the team.
It was a mixed methods approach that combined:
-
A platform-level CSAT and System Usability Scale (SUS) survey to anchor the baseline quantitative read on the existing Learning Hub.
-
Learner interviews and moderated user testing with that sample between March - April of 2025, structured around the most consequential journeys: finding content, deciding whether to engage, and getting through a module.
Synthesis was iterative: themes were shared with the design partner as they surfaced so design exploration could move in parallel.

Outcome
The redesign addressed the navigation and discoverability problems through several concrete changes. The most structural was expanding the library from courses-only to include individual modules and learning paths, recognizing that many users needed a single module rather than a full course sequence, and that the courses-only model was a structural mismatch with how people actually used the platform. Alongside that, the team added content tagging and filters by skill level (beginner, intermediate, advanced), product, and use case, making the catalog scannable in a way it hadn’t been before. A featured content section and a dedicated “New to Meraki” section gave first-time users an on-ramp that previously didn’t exist.
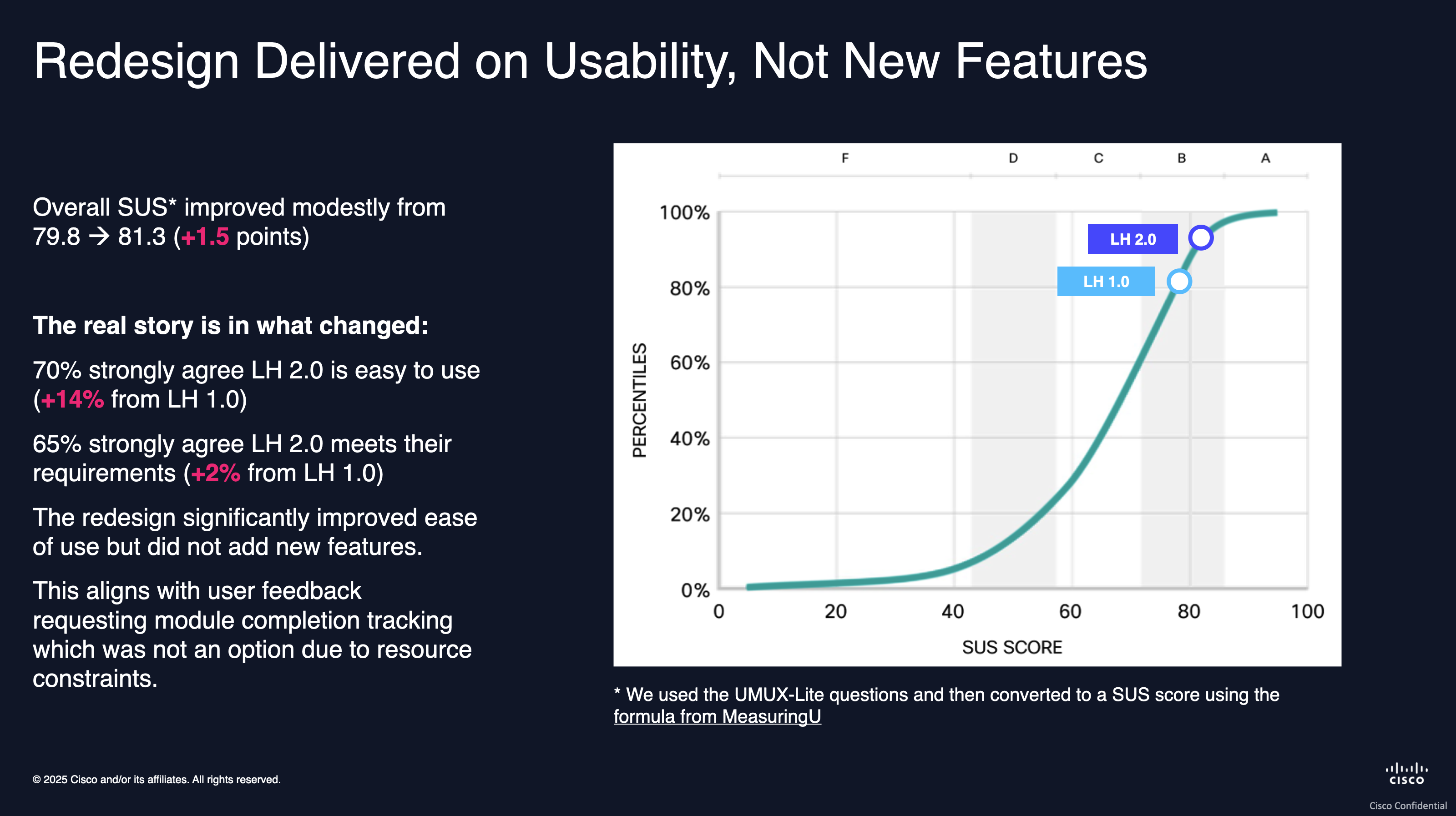
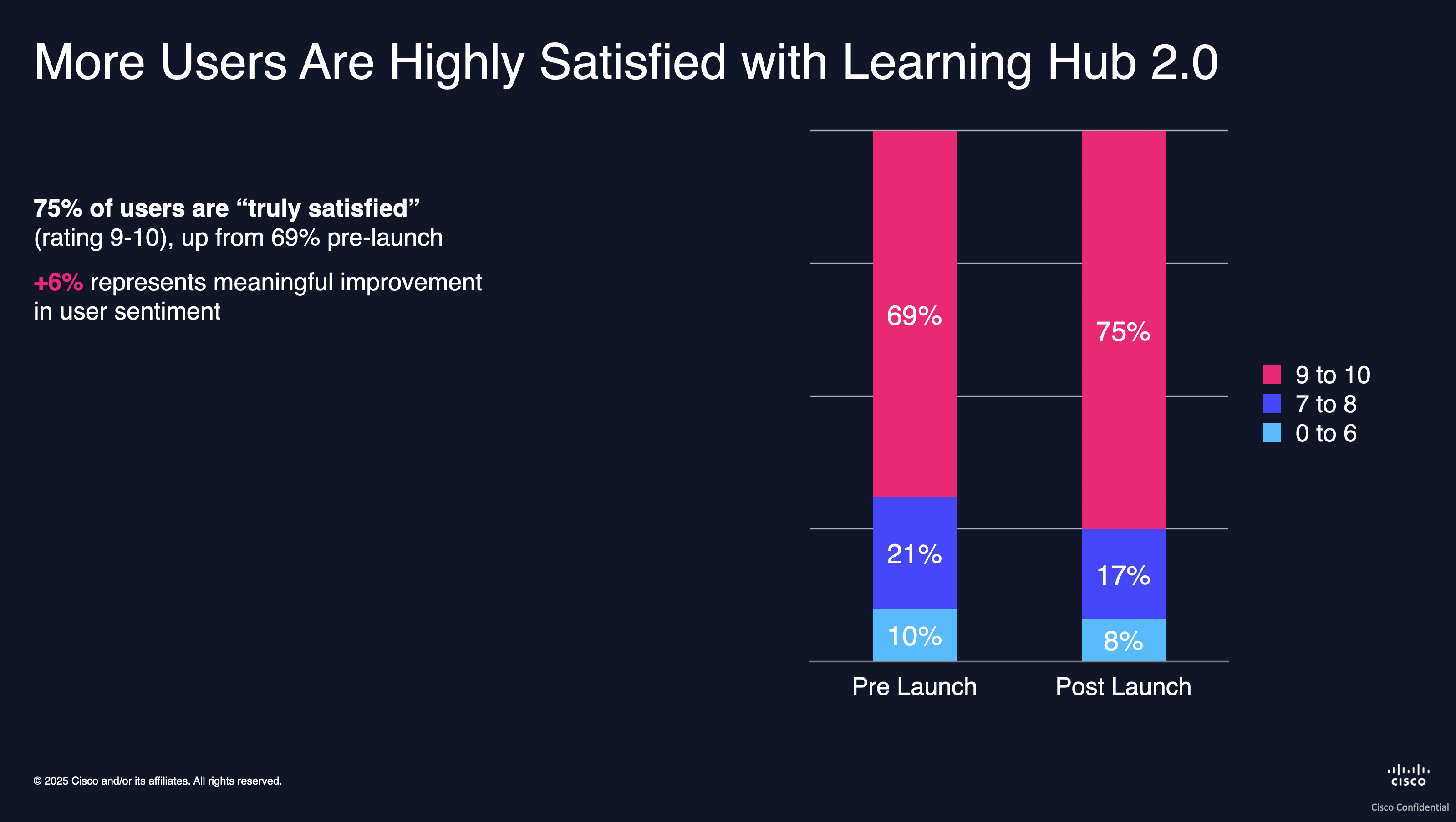
Because we ran the same CSAT and SUS instruments before and after the redesign went live, we could measure the change directly. Two numbers stood out:
- +14% on “the Learning Hub is easy to use”: the biggest single-item shift in the SUS battery, and a direct answer to the navigation and wayfinding problems surfaced in research.
- ~10% increase in users clicking through to start a course: total users held steady, so this reflects a real change in engagement: people who showed up and previously left without starting anything were now beginning coursework.
Content satisfaction was already high pre-2.0 and held steady post-launch. That was a useful signal in itself: it confirmed that the problem was navigational, not a question of content quality, which is exactly what participants had told us.
User Testing Insights report (PDF)
Reflection
Two things stood out from this project.
First, pairing SUS with CSAT gave the deliverable two complementary anchors. SUS let me speak to usability in a comparable, well-established metric; CSAT let me speak to overall sentiment in a metric the team already tracked. Running both before and after the redesign gave us a direct pre/post comparison rather than a one-time snapshot.
Second, the user testing surfaced something I didn’t expect: when scanning the catalog, users relied on titles and short descriptions far more than on images. The pattern was consistent: title first, description second, image last. They were skimming for keywords tied to their actual job: specific products, tasks, or problems they were actively dealing with. Images rarely changed what they clicked.
This mattered for design because we had assumed visual thumbnails would do more work in helping people identify relevance quickly. They didn’t, at least not for this population. Network administrators turned out to be text-first scanners, and that had direct implications for where to invest in content quality: a precise, keyword-rich title is worth more than a polished thumbnail. It’s worth noting this may be specific to this audience; a more visually-oriented learner population might scan differently.
This case study contains proprietary Cisco research. Enter the password to view.
Incorrect password.